Samiha Mirza
PhD Candidate in Computer Science · Applied Machine Learning · Data-Centric AI
About Me
I am a PhD candidate in Computer Science at the University of Houston, advised by Dr. Shishir Shah. My work focuses on applied machine learning, representation learning, and robustness for real-world, high-variability datasets.
My research focuses on data-centric AI: understanding how data quality, distribution shift, and structural variability influence model behavior. I design experimental frameworks and learning strategies that improve generalization, stability, and interpretability of deep learning systems, particularly for imaging and perception problems.
I have industry research experience at Shell, where I built end-to-end ML pipelines, conducted controlled experiments, and translated model outputs into actionable decision-support tools. Outside of work, I enjoy staying active, exploring new restaurants, traveling, and spending time with cats.
Education
-
PhD in Computer Science, University of Houston
Aug 2022 – Aug 2026 (expected) -
MS in Computer Science, University of Houston
June 2025
Selected Projects
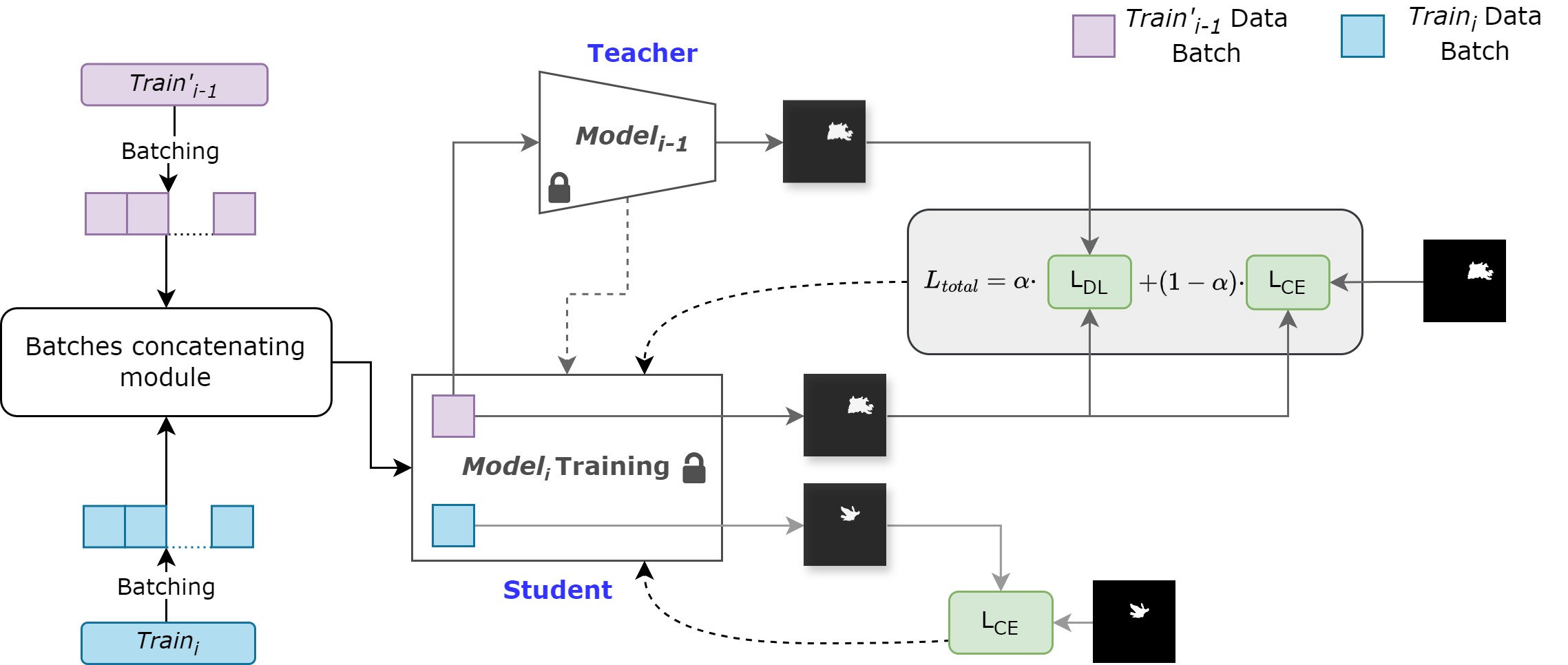
Continual Learning and Domain Adaptation via Knowledge Distillation for Robust Segmentation
This work investigates continual learning strategies for segmentation under realistic data distribution shift, where models are incrementally updated with new data distributions to mitigate catastrophic forgetting. A teacher–student distillation framework is proposed where prior model guides optimization of a student during later stages via a weighted loss. Ongoing work is focusing on utilizing CycleGANs to achieve domain adaptation
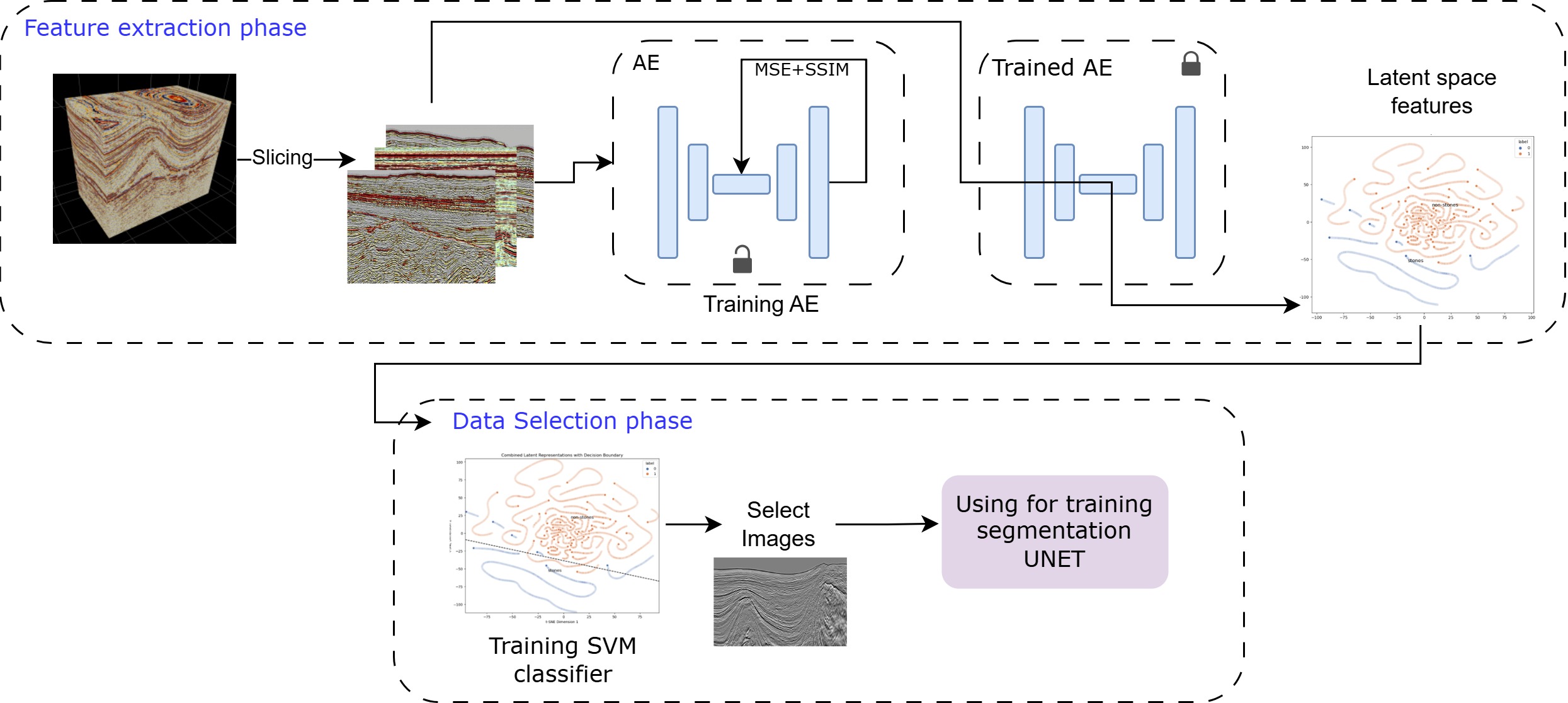
Autoencoder-Based Generative Latent Space Analysis for Data Selection
To achieve domain generalization while developing segmentation models, we train autoencoders to learn compact latent embeddings that capture dominant structural and textural patterns, and then use the encoder as a fixed feature extractor to project samples into a shared latent space. Generative latent-space structure is analyzed to identify outliers and underrepresented modes. A lightweight classifier (e.g., SVM) supports principled selection of informative samples for downstream segmentation, improving robustness under variability.
Paper ·
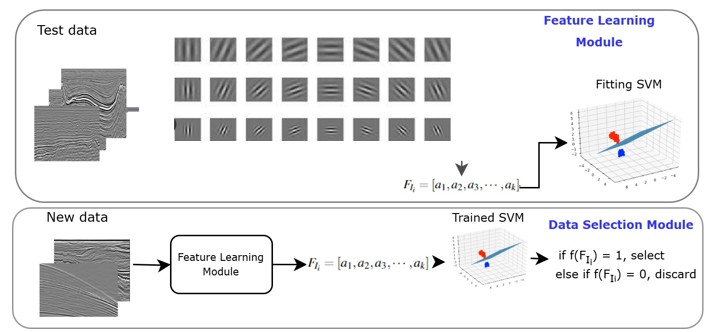
Data-Centric Quality Assessment for Robust Seismic Interpretation Models
This work studies how seismic data quality and label quality influence salt boundary segmentation under domain shift. We evaluate human-defined quality metrics and model-driven feature representations, and analyze their relationship to segmentation accuracy across datasets. Quality-aware data selection is integrated into the training workflow to improve robustness when generalizing to unseen domains, highlighting dataset curation as a first-class design choice in seismic interpretation pipelines.